
The curriculum is an ongoing series of workshops in which participants are introduced to technical, theoretical and methodological skills at the basis of the various practices that live within Varia. These are short intensive master-classes or workshops aimed towards providing high level introductions as a basis for further explorations.
Exploring computer text interfaces for better understanding, jokes and creativity.
Part of Varia Curriculum
18/10/2018
by Manetta Berends & Roel Roscam Abbing
For many the inner workings of a computer remain a mystery. One might know how to work on them, for example by making and storing texts or images but still be oblivious to what exactly happens when we do so. What is an image or text ‘made of’? And what are ways to use these formats of text and image in ways thar our usual GUI (Graphic User Interface) tools won’t allow us to?
This workshop aims to give the participants a better understanding of computer internals by learning about working with the command line. The command line is a text-only interface to your computer, which gives you a more explicit access to what is happening on your machine. Rather than clicking around you issue a variety of small text based commands to interact with your computer.
These text based commands are very simple and won’t really think for you like graphical programs do. For example, when those graphical programs tell you it is not possible to open that sound file in your photo editor they are thinking for you. Command line programs instead will allow you to just do that and assume you are doing the thinking.
While a bit awkward at first you will soon notice that working with and understanding the command line provides you with a lot of creative potential. Once you get used to these text-based utilities, it becomes an extremely fast way of working and navigating your computer. Additionally you will find that there is a large amount of useful utilities that exist for the command line, which you can not find in your GUI.
Perhaps the most important thing is that it will give you a window into understanding the workings of computers. Because many operating systems have a shared history as derivatives of the UNIX operating system, you will find that once you get an understanding of the command line on your own computer, you will easily manage to get around on other operating systems and computers in general2.
Although the command line is an old technology, it is wrong to think of the command line as old-fashioned. It is rather a completely different methodology for working on your computer. We will find that the command line is an interface and programming language at the same time.
‘The command line user interface provides functions, not applications; methods, not solutions, or: nothing but a bunch of plug-ins to be promiscuously plugged into each other.’3
While in the introduction we mentioned that text interfaces give a more ‘direct’ access to the computer’s internals, computers don’t actually work with text. Computers are calculators that work with numbers only. This means that any kind of input to the computer and any kind of output from the computer exists as numbers somewhere in between.
Based on this we can say that computers are nothing more than numbers, ‘wrappers and conventions’4.
Numbers because that is all what they understand. Wrappers as the packaging and software that process these numbers. Conventions because the way we process these numbers is not ‘natural’ or ‘neutral’ but rather the consequence of historical choices and agreements.
In order to understand a bit better what is happening in the computer we’ll start by unpacking (some of) the different ways that numbers are represented and used on a computer. This is useful because as we will see, letters and numbers don’t always represent what you’d think they represent.
The natural way of processing information for a computer is in ‘binary’ format. That is the consequence of the computer being a digital device and the computer’s hardware being able to only understand switches that are ‘on’ or ‘off’. The states of being on or off can be represented in ones and zeros or ‘true’ and ‘false’.
Even though we only have two ‘bits’ (0, 1) we can combine them to express all different kinds of numbers that computers can calculate on. In modern computers these bits are usually grouped together into ‘bytes’, which are series of 8 bits.
The downside of binary is that it is very difficult for humans to read and that you need a lot of bits to expres longer numbers:
In binary:
a zero is written as: 0
a one is written as: 1
a two is written as: 10
a three is written as: 11
a four is written as: 100
a five is written as: 101
a six is written as: 110
a seven is written as: 111
an eight is written as: 1000This is called a ‘base two’ counting system, meaning that we have 2 unique numbers in our counting system (including the 0). So counting a number higher than 1 we need to add one extra digit.
Grouping these numbers together in bytes lets us write it like so, which makes it much easier for us to read:
a zero is written as: 0000 0000
a one is written as: 0000 0001
a two is written as: 0000 0010
a three is written as: 0000 0011
a four is written as: 0000 0100
a five is written as: 0000 0101
a six is written as: 0000 0110
a seven is written as: 0000 0111
an eight is written as: 0000 1000
a sixteen is written as: 0001 0000
32 is written as: 0010 0000
64 is written as: 0100 0000
128 is written as: 1000 0000The binary system is also why so many things in computers are multiples of two. I’m sure any of the following numbers seem familiar to you if you think of the sizes of a USB-drive:
2, 4, 8, 16, 32, 64, 128, 256, 512, 1024 etcThese are all numbers wich are a power of two.
So a with a byte (8 numbers that can be one or two) we can represent up to 256 numbers (2^8).
In base two we use the following numbers:
0, 1And:
0 = 0000 0000
255 = 1111 1111The decimal system is another system for writing numbers and one that we are most familiar with. The decimal system is a base 10 system (meaning we can count up to 9 and then we need to add an extra digit). The advantage of the decimal system is that we’re very used to it and it is easy to work with your fingers.
In base 10 we use the following numbers:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9And:
0 = 0
255 = 255When working with computers however the hexadecimal number system is quite common. It is a base 16 number meaning we can express sixteen different numbers. It is used commonly because one can express four bits in one digit. It makes reading and writing binary much easier because there are less numbers to confuse us. The higher your numbers base, the bigger the number you can express with the same amount of characters.
In hexadecimal:
an eight is written as: 8
a nine is written as: 9
a ten is written as: A
an eleven is written as: B
a twelve is written as: C
a thirteen is written as: D
a fourteen is written as: E
a fifteen is written as: F
a sixteen is written as: 10
32 is written as: 20
64 is written as: 30
128 is written as: 40So in base 16 we use the following numbers:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, FAnd:
0 = 0
255 = FFYou will have likely encountered hexadecimal when selecting colors in CSS or in your photo editor. In those cases the color white is sometimes described as FFFFFF and red as FF0000. That is because these color systems use three values to express Red, Green and Blue which are each eight bit, ranging from 0 to 255. So FFFFFF equals 255 255 255 and FF0000 equals 255, 0, 0
Above we’ve outlined three different numerical systems. It is important to repeat that these are three different ways of writing the same number! So:
1111 1111 = 255 = FF
It is good to know because you might come across DEAD BEEF and feel insecure about whether this is about the decimal number 3735928559 or not. Similarly, when encountering 1000 it mightnot be clear whether you’re looking at the binary form of 8, the decimal form of 1000 or de hexadecimal form of 4096. This is why it is common to prefix hexadecimal numbers with 0x, that way it is clear what is meant when you read 0xDEADBEEF.
The process of converting from one type of information to another is called encoding. You can think of it as a similar process to Morse Code where longer and shorter beeps represent letters5.
Or the process of dialing a phone number, where pressing the keys generate a specific sound which tells the computers at the phone central who to connect you to.
Using the technique of encoding and decoding binary numbers can be made to represent everthing you see on the computer. There are standards, conventions which describe how something should be encoded and decoded so that one type of information can be translated in multiple places.
n.b. That encoding is not the same as encrypting! In the process of encoding the mapping between the code and the desired result are known and communicated. In encryption that mapping is purposely kept a secret.
As a computer can only work with numbers, it cannot process of letters text directly. In order to work with text, textual characters need to be translated into numbers and vice versa. This is done via the process of text encodings.
It might be your first reaction to think that this shouldn’t be so difficult. We could represent the letter in binary code. An a encoded as a 0, b as a 1 and c as a 01 etc. And in fact this is more or less how text encodings work. However, at the time when computing was being developed different encodings emerged.

 US-ASCII Code Chart (source)
US-ASCII Code Chart (source)
The dominant encoding at the time became ASCII (for American Standard Code for Information Interchange.), which was created on behalf of the U.S. Government in 1963 to allow for information interchange between their different computing systems.
The encoding uses a 7-bit system, which means that they could only store characters in 128 (2^7=128) numbers (0000 0000 until 0111 1111). The resulting encoding schema assigned to each of these 128 numbers:
Thanks to the simplicity of the encoding it quickly became a standard for the American computing industry.
Thanks to the power of the US Military and US corporations the American computing industry became the global computing industry. Computers that we use today are rooted in American networking history, and so is the ASCII standard. However, the reality is that ASCII can only represent 26 Latin letters in the English alphabet but computers are used all over the world, by people speaking different languages. They would often end up with American computers that could not represent their language in ASCII. Think for example of scripts like Greek, Cyrillic and Arabic or even Latin scripts that use accents such as the ü or ø. Altough 128 might sound like a lot of characters, it is not enough to represent all different languages.
What happens when you open a document with the wrong encoding is demonstrated in this exercise.
Or you can try this:
$ python2.7 -c "print 'ø'.encode('ascii')"
For a time people used the 8th bit, numbers 1000 0000 to 1111 1111 (or 128 to 256) to encode the specific parts of their own language. That way there was an overlap with ASCII but the own language could also be encoded.
A list of all the 128 ASCII characters, and their corresponding numbers can be seen in this table:
Binary Dec Hex Char Binary Dec Hex Char
────────────────────────────────────────────────────────────────────────────────
0000 0000 0 00 NUL '\0' (null character) 0100 0000 64 40 @
0000 0001 1 01 SOH (start of heading) 0100 0001 65 41 A
0000 0010 2 02 STX (start of text) 0100 0010 66 42 B
0000 0011 3 03 ETX (end of text) 0100 0011 67 43 C
0000 0100 4 04 EOT (end of transmission) 0100 0100 68 44 D
0000 0101 5 05 ENQ (enquiry) 0100 0101 69 45 E
0000 0110 6 06 ACK (acknowledge) 0100 0110 70 46 F
0000 0111 7 07 BEL '\a' (bell) 0100 0111 71 47 G
0000 1000 8 08 BS '\b' (backspace) 0100 1000 72 48 H
0000 1001 9 09 HT '\t' (horizontal tab) 0100 1001 73 49 I
0000 1010 10 0A LF '\n' (new line) 0100 1010 74 4A J
0000 1011 11 0B VT '\v' (vertical tab) 0100 1011 75 4B K
0000 1100 12 0C FF '\f' (form feed) 0100 1100 76 4C L
0000 1101 13 0D CR '\r' (carriage ret) 0100 1101 77 4D M
0000 1110 14 0E SO (shift out) 0100 1110 78 4E N
0000 1111 15 0F SI (shift in) 0100 1111 79 4F O
0001 0000 16 10 DLE (data link escape) 0101 0000 80 50 P
0001 0001 17 11 DC1 (device control 1) 0101 0001 81 51 Q
0001 0010 18 12 DC2 (device control 2) 0101 0010 82 52 R
0001 0011 19 13 DC3 (device control 3) 0101 0011 83 53 S
0001 0100 20 14 DC4 (device control 4) 0101 0100 84 54 T
0001 0101 21 15 NAK (negative ack.) 0101 0101 85 55 U
0001 0110 22 16 SYN (synchronous idle) 0101 0110 86 56 V
0001 0111 23 17 ETB (end of trans. blk) 0101 0111 87 57 W
0001 1000 24 18 CAN (cancel) 0101 1000 88 58 X
0001 1001 25 19 EM (end of medium) 0101 1001 89 59 Y
0001 1010 26 1A SUB (substitute) 0101 1010 90 5A Z
0001 1011 27 1B ESC (escape) 0101 1011 91 5B [
0001 1100 28 1C FS (file separator) 0101 1100 92 5C \ '\\'
0001 1101 29 1D GS (group separator) 0101 1101 93 5D ]
0001 1110 30 1E RS (record separator) 0101 1110 94 5E ^
0001 1111 31 1F US (unit separator) 0101 1111 95 5F _
0010 0000 32 20 SPACE 0110 0000 96 60 `
0010 0001 33 21 ! 0110 0001 97 61 a
0010 0010 34 22 " 0110 0010 98 62 b
0010 0011 35 23 # 0110 0011 99 63 c
0010 0100 36 24 $ 0110 0100 100 64 d
0010 0101 37 25 % 0110 0101 101 65 e
0010 0110 38 26 & 0110 0110 102 66 f
0010 0111 39 27 ' 0110 0111 103 67 g
0010 1000 40 28 ( 0110 1000 104 68 h
0010 1001 41 29 ) 0110 1001 105 69 i
0010 1010 42 2A * 0110 1010 106 6A j
0010 1011 43 2B + 0110 1011 107 6B k
0010 1100 44 2C , 0110 1100 108 6C l
0010 1101 45 2D - 0110 1101 109 6D m
0010 1110 46 2E . 0110 1110 110 6E n
0010 1111 47 2F / 0110 1111 111 6F o
0011 0000 48 30 0 0111 0000 112 70 p
0011 0001 49 31 1 0111 0001 113 71 q
0011 0010 50 32 2 0111 0010 114 72 r
0011 0011 51 33 3 0111 0011 115 73 s
0011 0100 52 34 4 0111 0100 116 74 t
0011 0101 53 35 5 0111 0101 117 75 u
0011 0110 54 36 6 0111 0110 118 76 v
0011 0111 55 37 7 0111 0111 119 77 w
0011 1000 56 38 8 0111 1000 120 78 x
0011 1001 57 39 9 0111 1001 121 79 y
0011 1010 58 3A : 0111 1010 122 7A z
0011 1011 59 3B ; 0111 1011 123 7B {
0011 1100 60 3C < 0111 1100 124 7C |
0011 1101 61 3D = 0111 1101 125 7D }
0011 1110 62 3E > 0111 1110 126 7E ~
0011 1111 63 3F ? 0111 1111 127 7F DEL(based on $ man ascii)
Decode the following binary code:
0100 1000
0110 0101
0110 1100
0110 1100
0110 1111
0010 0000
0101 0111
0110 1111
0111 0010
0110 1100
0110 0100
0010 0001’As electronic text was increasingly being exchanged online and between language areas, issues emerged when text encoded in one language was shared and read on systems assuming an encoding in another language. Unicode was a response to the incompatible text encoding standards that were proliferating.
When different encodings assign the same binary numbers to different characters, this results in illegible documents. The solution, partly made possible by increased computing capacity, was to strive for a single universal encoding which would encompass all writing systems’ 6
You can experience this following this exercise.
So in order to overcome the limitations of ASCII people created the Unicode Consortium to create a single universal character encoding:
‘The Unicode standards are designed to normalise the encoding of characters, to efficiently manage the way they are stored, referred to and displayed in order to facilitate cross-platform, multilingual and international text exchange. The Unicode Standard is mammoth in
size and covers well over 110,000 characters, of which [..] 1,000 are [..] emoji.’ 7
In effect the Unicode Standard combined all the different national character encodings together into a single large ledger in order to try to represent all languages.
It is divided in so called blocks, which are basically number tables that describe which number is connected to which character.
The table starts counting at 0x0 and continues all the way up to 0x10FFFF.
The first block actually corresponds with ASCII:
https://en.wikibooks.org/wiki/Unicode/Character_reference/0000-0FFF
It contains many different scripts for supporting large and smaller language groups, including for example Ethiopian and Cherokee:
https://en.wikibooks.org/wiki/Unicode/Character_reference/1000-1FFF
However there are also blocks that describe Arrows and other symbols:
https://en.wikibooks.org/wiki/Unicode/Character_reference/2000-2FFF
Emoji are also part of the unicode table.
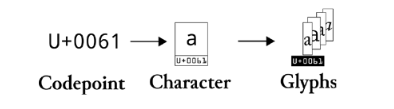
In the Unicode standard every text character has a representation as a number or codepoint. The standard defines what codepoint is connected to what character, but not what glyph should look like. That is left to individual font designers.
Next to the letters, there are many control characters that are used for example to display text from right to left and reverse or to join two separate characters together into one (as happens with Asian language scripts)
One of the curious things about Unicode is that there are many homographs (characters look identical, have different code points).
For example: Greek Ο, Latin O, and Cyrillic О are identical to the eye, but different to the computer.
You can tell when you take a closer look:
`Ο` = `0x39f` for Greek
`O` = `0x4f` for Latin
`О` = `0x41e` for CyrillicTry to copy the Greek or Cyrillic О and search for it in the document by pressing ctrl + f and entering it in the search bar. Then do the same with the Latin O.
Here is a piece of python code that will fill try to print out all Unicode characters by counting from 0x0 to 0x10FFFF and converting that into a printable character:
$ python -c 'exec """\nimport time\nwhile True:\n for i in range(0x0,0x10FFFF):\n print unichr(i)*80\n time.sleep(0.05)\n"""'
With this technique it is also possible to make animations: $ python -c 'exec """\nimport time\nwhile True:\n for i in range(127761,127768):\n print unichr(i)*10\n time.sleep(0.05)\n"""'
CMD+S or CTRL+S for this.<meta http-equiv="content-type" content="text/html; charset=UTF-8"> and change the encoding of the document from UTF-8 into ASCII.You have now Mojibaked8 the page!
On top of the text encoding standards, a next layer of conventions is found in file encodings. In order to open a file, the computer needs to be told what filetype it is and how to interpret the data in the file.
One of the things that it uses to do so is the file extension, you are probably familiar with them! Common extensions are .jpeg, .pdf or .txt for a plain text document.
Next to a file extension, more detailed information about the file is included in a file header. The file header includes metadata about the file and it specifies how the data is encoded.
For example, the header convention for HTML files is the following line:
<!DOCTYPE html>Not all the file headers and file encodings are as easy to read and/or write manually. HTML is for example designed to be read and written directly, but a file format such as JPEG is very complicated to write or read directly. This is because we would probably never write a JPEG file manually, but produce them with a camera or through image editing software.
As an exercise in file encoding, we will digitize a piece of pixel art drawn on paper into a digital image file following the Netpbm format.
The underlying format of Netpbm is PBM, a file format designed in the ’80s. At the time PBM made it possible to include images in the 7-bit ASCII encoded emails. It was replaced in the ’90s by Netpbm.
We’re using Netpbm as it is a clear file format that we can manipulate with a text editor. IRL you won’t be working with this file format too much (if not not at all), but its simple data structure makes it an interesting tool for learning purposes.
We will write our image pixel-by-pixel. Our image will have a width of 5 pixels and a height of 7 pixels, to keep this exercise doable in a short amount of time. :) For each pixel we will write a RGB (Red, Green, Blue) color code, as this is the color space of screens. This means that every pixel will be described by 3 numbers that range between 0 and 255, the first number representing the amount of red in the pixel (0-255), the second for the amount of green (0-255) and the third for the amount of blue (0-255).
The following code is an example Netpbm image. It shows how the image below is written following the Netpbm encoding convention.
P3 5 7 255 # The part above is the header # "P3" means this is a RGB color image in ASCII # "5 7" is the width and height of the image in pixels # "255" is the maximum value for each color # The part below is image data: RGB triplets 255 0 0 255 0 0 255 0 0 255 0 0 255 0 0 0 0 255 0 0 255 255 0 0 0 0 255 0 0 255 255 0 0 0 0 255 255 0 0 0 0 255 255 0 0 255 0 0 0 0 255 255 0 0 0 0 255 255 0 0 255 0 0 0 0 255 255 0 0 0 0 255 255 0 0 255 0 0 255 0 0 0 0 255 255 0 0 255 0 0 255 0 0 255 0 0 255 0 0 255 0 0 255 0 0
Netpbm example data

Step-by-step
red in RGB is 255 0 0, or blue is 0 0 255..txt), not as Richt Text Format (.rtf) or Word document (.docx)..pbm extension. An example: my-image.pbm.Go ahead and start using the command line by opening a terminal application. You’ll see a text interface with a blinking cursor. What happened when you opened the terminal is that it actually opened a so-called shell for you. The shell (sh) is a software which takes your keyboard input and gives it to the computer’s operating system. There are various types of shells but the most common ones are bash (bourne again shell) or zsh.
So what exactly are we looking at?
After having opened the terminal you will be greeted by the following prompt:
r@badjak:~$
[Bob@MacBook-Pro-van-Bob: ~]%
MacBook-Pro-van-Anna:~ anna$
This is the main interface and it tells you a few things:
r @ computer badjak~. This is a UNIX shorthand for the user’s home folder, in our example’s case /home/r/$), denoting that after that symbol your input follows.In many examples and tutorials you will encounter the dollar sign in lines that are meant to be copied. However don’t copy it, with the dollar we simply mean to say: after $ type the following. It is used to indicate we are talking about a CLI command. So when you encounter:
$ cd ~/
The actual command to type is
cd ~/
The interesting things about shells is that they are simultaneously interfaces and programming languages. Text typed in the shell can represent commands, data or just text.
Try typing hello for example:
$ hello
bash: hello: command not found
All words or characters typed into the shell are interpreted as commands.
So if you want to print text, use echo.
$ echo 'hello!'
hello!
Echo is in fact a little programme that allows us to display text, transforming whatever is typed from 'command' to 'text'.
A typical CLI command might look like this:
$ ls -al ~/Downloads/
Let’s analyze the above. A command issued follows this pattern:
$ command -flags arguments
The command is the name of the program to use, the flags are the ‘options’ for the command and the argument is what you use the command on. So in the case of the above, the command is:
$ ls
The flags are:
$ -al
The argument is:
$ ~/Downloads/
One of the confusing things initially about the command line is that it doesn’t give you a lot of feedback. So if you input a command, seemingly nothing might happen. This is usually a good thing. If your command gives you some output, it is usually something to take note of as something might be going wrong.
A command to tell us where we are at the moment. Used to find our present working directory.
$ pwd
Moving to another directory is done with the change directory command:
$ cd foldername
For example moving to your desktop:
$ cd ~/Desktop/
The UNIX command line uses a lot of shorthands. We’ve already encountered \~ for homefolder. But there are also \..\ which means 'one back' and . which means 'here' Move to your homefolder:
$ cd ~
Move to the parent folder, one folder up:
$ cd ../
Move two folders up:
$ cd ../../
Copy a file from your downloads folder to the folder you are currently in:
$ cp ~/Downloads/omg.zip .
As you can see you can make copies of files with cp. This means that after copying you have two files.
You can also move a file like this. You then only have one file:
$ mv ~/Downloads/omg.zip ~/
To know where you are you can also look around in a folder with the list command. It will print out all the files in the folder for you:
$ ls
Another shorthand is *. It stands for ‘any’ and can be used to filter specific things. Lets move all files into a folder:
$ mv ~/Downloads/* ~/Files/
The * can also be used to match patterns. Lets for example move all .jpgs in to another folder:
$ mv ~/Downloads/*.jpg ~/Pictures/
*.jpg will match any filename with the extension .jpg
Let’s delete (remove) all the jpgs that start with IMG_ from the Downloads folder:
$ rm ~/Downloads/IMG_*.jpg
Careful with that, rm will not tell warn you and it will not move things to trash, but really delete the files.
One of the really powerful things about the command line is that different little programs can be chained together. This is done through 'output redirection' or 'piping'. This allows the output of one program to become the input of the other. These input and outputs are also called stdin and stdout (or standard in, standard out). The reason all these programs work together is because they adhere to the UNIX design philosophy9 where programs do one thing and do them well and expect the output of every program to become the input to another.
Look at the following command:
$ ls -al *.html | grep 'Sep' > files_from_september.txt
The following symbols are for output redirection:
Pipe from one program to the other: $ ls|grep
(Over)write output to file: $ grep 'Sep'>files_from_september.txt
Append ('add') output to file: $ grep 'Sep'>>files_from_september.txt
So when we know all of the above we can start to understand the meaning of:
$ ls -al *.html | grep 'Sep' > files_from_september.txt
The command line has a built in documentation system which allows you to look up how to use a program. For example we never explained what the command 'grep' does exactly. However you can read its manual like so:
$ man grep
By doing so we will get the following output:
NAME
grep, egrep, fgrep, rgrep - print lines matching a pattern
SYNOPSIS
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN]... [-f FILE]... [FILE...]
DESCRIPTION
grep searches the named input FILEs for lines containing a match to
the given PATTERN. If no files are specified, or if the file “-” is
given, grep searches standard input. By default, grep prints the
matching lines.
In addition, the variant programs egrep, fgrep and rgrep are the same
as grep -E, grep -F, and grep -r, respectively. These variants are
deprecated, but are provided for backward compatibility.
Here we learn that grep is a pattern matching program. In the Synopsis we can see the basic use. Use your up and down keys to navigate the manual and use q to exit.
Files can be read (also called printed) on the terminal with cat. This stands for concatenate, which is a fancy way of saying, read the file line byline and add the outputs to each other
$ cat myfile.txt
Sometimes your terminal gets full of output that it becomes difficult to read. Clear it like so:
$ clear
Some files or outputs are really long and you might want to be able to scroll back and forth through them to read:
$ cat longassfile.txt | less
Like the manual, use the arrow keys to navigate and q to quit.
The terminal is not only for reading you can also write files:
$ nano myfile.txt
This will give you an interactive interface where you can start typing in myfile.txt. When you are done press ctrl+o to save the file (write out) and ctr+x to exit the interactive editor.
We can also edit the output of one command with sed, the stream editor. This is a sort of find-and-replace command.
$ echo 'Hey you!' | sed 's/you/everyone/g'
Hey everyone!
By using this knowledge we can make custom tools by just adding small commands together. This is known as making bash scripts. It’s also a very useful way to save your commands as files, so you don’t have to remember them by heart.
Let’s start making one.
Create a text file called CAPS.sh (.sh is the file extension for bash scripts).
Write the following:
Save it.
tr is a small programm to do text format translations. We use it to turn lowercase letters [a-z] into [A-Z].
Now we made a program that turns every text into full caps!
$ echo 'Hey there, what are you up to?' | sh CAPS.sh
HEY THERE, WHAT ARE YOU UP TO?
And following the pipeline logics, you can now write the results to a plain text file, by adding the >.
echo 'Hello World' | sh CAPS.sh > helloworld.txt
To extend your toolset, you can download all sort of packages. These packages are collected by so called package managers. The package manager of Debian & Ubuntu (two Linux distributions) is called apt. On Mac you can use brew which is the shorter name for homebrew.
To install Homebrew, visit https://brew.sh and follow the instructions.

$ figlet - use ASCII art fonts, jeej! Try it like this: echo 'test' | figlet$ espeak in Linux, or $ say in Mac - listen to your text files. Try it like this: $ echo 'Hello World!' | espeak or $ echo 'Hello World! | say$ date - print the current date$ nano - command line text editor$ wget - a tool to download pages or files from the web as files$ curl - a tool to write pages or files to your terminal$ lpr (not sure if this works in Mac) - pipe plain text directly to the printer
$ lpstat -p -d$ lpoptions -d PRINTERNAME$ cat YOURTEXTFILE.txt | lpr -o portrait -o fit-to-page -o media=A4$ calendar - never forget to celebrate today and tomorrow$ history - shows your last shell commands$ youtube-dl - download youtube video’s before they are not available anymore!$ touch - touch a file (to modify its modification date), or use this tool to create new files$ df -h - see how much diskspace you have left$ du - see what huge files are filling up this disk space$ tree - print nice mappings of your folder structures$ pandoc - your swiss-army knife to convert documents from the one mark-up to the other$ pdftk - another$ pdfunite - merge multiple pdf’s into one$ pdftotext - extract text from PDFs and save it as a .txt file (Note: this only works with PDFs that contain plain text in them. Some PDFs are made of images only, ans hence this tool cannot extract plain text from them)Now you can download the a page of the New York Times, improve it and read it:
$ curl$ sed, do search (Trump) and replace (Dumb).html file&& to glue another command to this pipeline, and let your browser (for example $ firefox) open the .html you just saved$ curl https://www.nytimes.com | sed 's/Trump/Dumb/g' > nyt.html && firefox nyt.html
Use a small unicode replacements for the space character to circumvent copyright.
$ pdftotext to convert a PDF to plain text file&& we glue it to another command, in which we open the text file again, using $ cat$ sed again to replace the space character for another unicode character> to write the new text to a file$ pdftotext language.pdf && cat language.txt | sed -r 'y/ / /' > language-bypassed.txt
Tip: This is a good webpage to pick your favourite type of space: http://jkorpela.fi/chars/spaces.html
You could make a custom glitch converter program, by replacing letters with other unicode characters.
$ pdftotext to convert a PDF to plain text file. This tool takes a .pdf file and writes a .txt file with the same filename.&& we glue it to another command, in which we open the .txt file again, by using $ cat$ sed again to replace some letters for other unicode characters that are look-a-likes> to write the new text to a file$ pdftotext language.pdf && cat language.txt | sed -r 'y/a/შ/' > language-glitched.txt
Tip: This is a good source to find characters for you own custom converter: https://en.wikipedia.org/wiki/Mathematical_operators_and_symbols_in_Unicode
A next step would be to make a bash script to save your converter as a program, which makes it easier to use your converter for future customized text!
.sh bash script, for example: converter.shsed command into the file.Try it in the terminal:
$ cat language.txt | sh converter.sh
Write a pipeline around your converter in the terminal, to test if it works!
$ cat to open a plain text file.sh converter bash script>$ cat language.txt | sh my-glitch-converter.sh > language-glitched.txt
Combine your Netpbm skills with some GIFmagic!
You can use Imagemagick software to turn a folder of .pbm images into a .gif. Imagemagick is a very powerful set of tools to work with images through the command line. $ convert is one of the tools of the Imagemagick toolset.
$ brew install imagemagick
or
$ apt install imagemagick
Now you’re ready to make gif files!
.pbm image files. Tip: you can use the search-and-replace tool of your text editor to make quick versions of your first image.For example:
convert command of Imagemagick to make a .gif file.$ convert image1.pbm image2.pbm image3.pbm image.gif
or shorter:
$ convert image*.pbm image.gif

More options and examples can be found on the Imagemagick page about gifs: http://www.imagemagick.org/Usage/anim_basics/#gif_anim.
This reader was collaboratively edited as an Etherpad-Lite which is downloaded and converted into a HTML document with Pandoc. The styling for the HTML document lives on another pad.
See the command for that below:
$ curl https://pad.vvvvvvaria.org/curriculum.cli.reader.css/export/txt > stylesheet.css && curl https://pad.vvvvvvaria.org/curriculum.cli.reader/export/txt | pandoc -f markdown -t html --toc -H stylesheet.css -s -o reader.command-lines.html && rm stylesheet.css On the cultural specificity of ASCII and ‘plain text’:
On Unicode’s universal understanding of a world full of particularities:
On all the languages that are still not in Unicode:
On the history of word processors:
http://faculty.georgetown.edu/irvinem/theory/Stephenson-CommandLine-1999.pdf↩
Microsoft Windows in this case is a stranger in our midst, it doesn’t share the UNIX history so the commands and logic are not the same as for Macintosh and Linux. The Windows cmd.exe however still gives you this more explicit access to your computer.↩
(echo echo) echo (echo): Command Line Poetics by Florian Cramer↩
Ted Nelson (2012) Computers for Cynics 0 - The Myth of Technology - video log on Youtube↩
Exercise: try to use this to decode this: …. . .-.. .-.. —- .– —- .-. -..↩
Roel Roscam Abbing, Peggy Pierrot, Femke Snelting (2016?), Modifying the Universal↩
Roel Roscam Abbing, Peggy Pierrot, Femke Snelting (2016?), Modifying the Universal↩
http://www.faqs.org/docs/artu/ch01s06.html↩
{kind=link}
{kind=link}
{kind=link}